Гистограммы и вероятность
В некоторых ситуациях гистограмма не дает нужной нам информации. Мы можем посмотреть на гистограмму и легко определить частоту измеренного значения, но не можем легко определить вероятность измеренного значения.
Например, если я посмотрю на первую гистограмму, я знаю, что примерно 8000 измерений показали разницу в 0 В между номинальным и фактическим напряжениями стабилизатора, но я не знаю, какова вероятность того, что результат случайно выбранного измерения или нового измерения сообщит о разнице в 0 В.
Это серьезное ограничение, потому что вероятность отвечает на чрезвычайно распространенный вопрос: каковы шансы, что…?
Каковы шансы, что у моего линейного стабилизатора погрешность выходного напряжения будет менее 2 мВ? Какова вероятность того, что частота битовых ошибок моего канала передачи данных будет выше 10-3? Какова вероятность того, что из-за шума мой входной сигнал превысит порог срабатывания? И так далее.
Причина этого ограничения заключается в том, что гистограмма просто четко не передает размер выборки, то есть общее количество измерений (теоретически общее количество измерений можно определить, сложив значения всех столбцов гистограммы, но это было бы утомительно и неточно).
Если мы знаем размер выборки, мы можем разделить количество появлений на размер выборки и таким образом определить вероятность. Давайте рассмотрим пример.
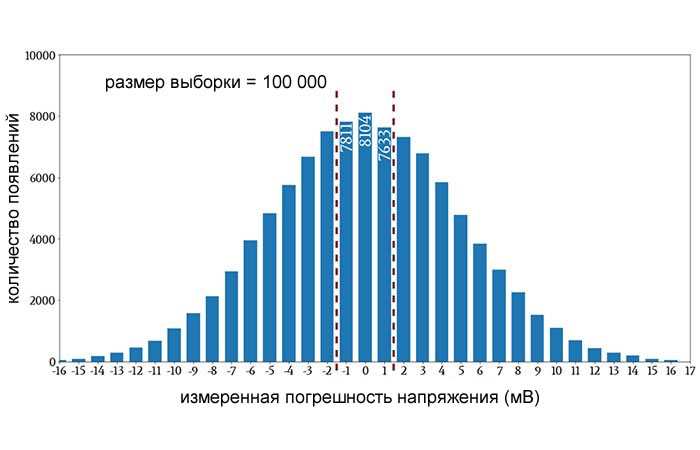 Рисунок 3 – Пример того, как гистограмма может помочь нам определить вероятность путем деления количества появлений на размер выборки
Рисунок 3 – Пример того, как гистограмма может помочь нам определить вероятность путем деления количества появлений на размер выборки
Красные пунктирные линии заключают в себя столбцы, которые указывают на погрешности напряжения менее 2 мВ, а числа, написанные внутри столбцов, указывают точное количество появлений этих трех значений погрешности напряжения. Сумма этих трех чисел составляет 23 548. Таким образом, на основе этого примера по сбору данных вероятность получения погрешности менее 2 мВ составляет 23 548/100 000 ≈ 23,5%.
Контрольные листки
Учитывая системный характер работ по выявлению некачественной продукции, на многих предприятиях разработаны типовые бланки для заполнения информации о наблюдениях. Такой форме регистрации данных отвечает контрольный листок – бумажный бланк, на котором заранее напечатаны контролируемые параметры, с тем, чтобы можно было легко и точно записать данные наблюдений или измерений. Его назначение имеет две цели: облегчить процесс сбора данных и упорядочить их для последующей обработки.
Рассмотрим некоторые типы контрольных листков в зависимости от назначения сбора информации.Контрольный листок для регистрации видов дефектов. Каждый раз, когда рабочий или контролер обнаруживает дефект, он делает пометку (штрих) на бланке. На том же бланке в конце рабочего дня фиксируются итоговые данные по количеству каждого типа дефектов.
|
Типы дефектов |
Группы |
Итого |
|
Трещины |
//// //// |
10 |
|
Царапины |
//// //// //// ////…//// // |
42 |
|
Пятна |
//// / |
6 |
|
Деформация |
//// //// //// ////…//// //// |
104 |
|
Разрыв |
//// |
4 |
|
Раковины |
//// //// //// //// |
20 |
|
Прочие |
//// //// //// |
14 |
|
Итого |
200 |
Рис. Контрольный листок видов дефектов
К недостаткам этого листка можно отнести невозможность проведения расслоения данных.
Это недостаток можно компенсировать заполнением контрольного листка причин дефектов. Листок выполнен таким образом, чтобы из него можно было выбрать необходимую информацию о дефектах, допущенных не только по вине рабочего или по причине неправильной наладки станка, но и определить появление брака, вызванное усталостью рабочего во второй половине дня или изменением условий работы. Очевидно, что анализ причин дефектов при такой регистрации данных значительно облегчается.
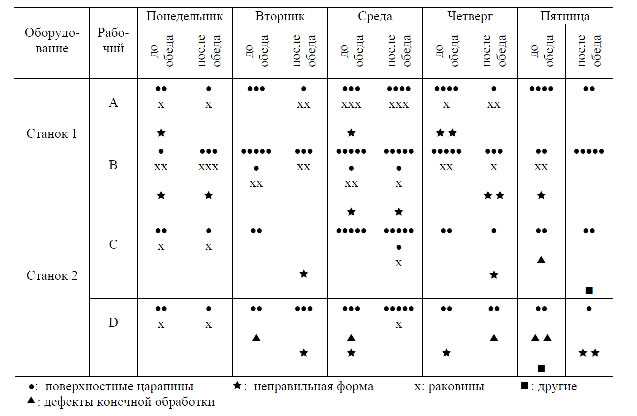
Рис. Контрольный листок причин дефектов
Контрольный листок локализации дефектов позволяет оценить качество отливки на наличие раковин как вдоль оси заготовки, так и по длине ее наружной и внутренней поверхностей. Такого типа контрольные листки полезны для диагноза процесса, поскольку причины дефектов часто можно найти, только исследуя места их возникновения.
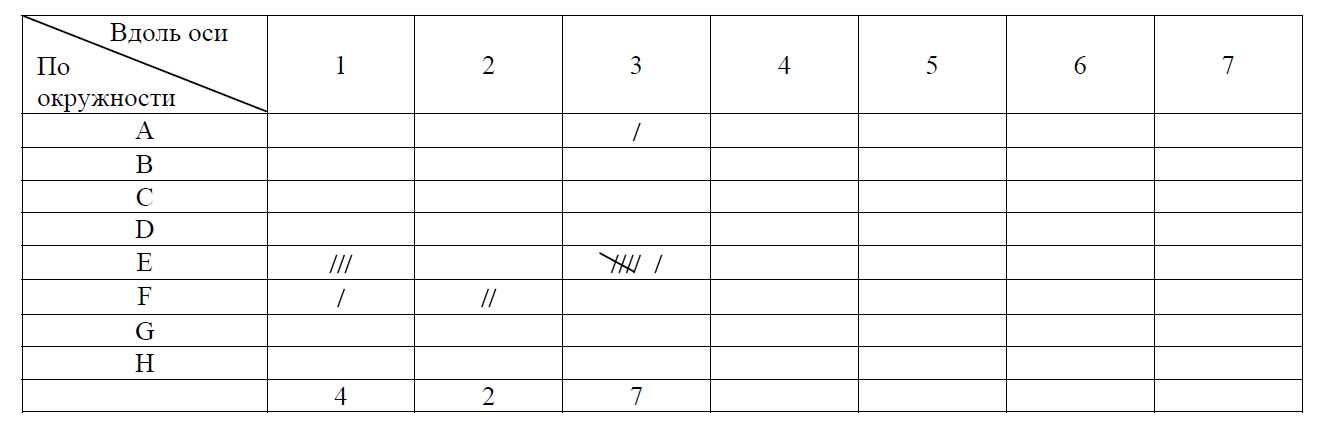
Рис. Контрольный листок локализации дефектов
Контрольный листок для регистрации распределения измеряемого параметра позволяет выявить изменения в размерах детали после проведения механической обработки. Как правило, такие листки заполняются для анализа стабильности технологического процесса путем построения гистограмм.
Частота
Частота это число, которое показывает сколько раз в выборке встречается тот или иной элемент.
Предположим, что в школе проходят соревнования по подтягиваниям. В соревнованиях участвует 36 школьников. Составим таблицу в которую будем заносить число подтягиваний, а также число участников, которые выполнили столько подтягиваний.
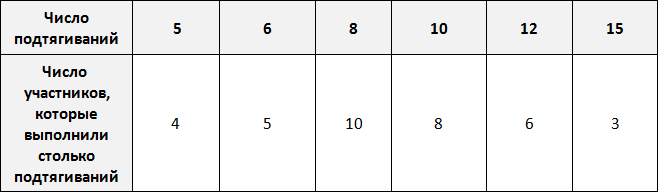
По таблице можно узнать сколько человек выполнило 5, 10 или 15 подтягиваний. Так, 5 подтягиваний выполнили четыре человека, 10 подтягиваний выполнили восемь человек, 15 подтягиваний выполнили три человека.
Количество человек, повторяющих одно и то же число подтягиваний в данном случае являются частотой. Поэтому вторую строку таблицы переименуем в название «частота»:

Такие таблицы называют таблицами частот.
Частота обладает следующим свойством: сумма частот равна общему числу данных в выборке.
Это означает, что сумма частот равна общему числу школьников, участвующих в соревнованиях, то есть тридцати шести. Проверим так ли это. Сложим частоты, приведенные в таблице:
4 + 5 + 10 + 8 + 6 + 3 = 36
Гистограммы с интервалами
Когда набор данных содержит так много разных значений, что мы не можем удобно связать их с отдельными столбцами гистограммы, мы используем объединение в интервалы (биннинг). То есть мы определяем диапазон значений как интервал, группируем результаты измерений в эти интервалы и создаем по одному столбцу для каждого интервала.
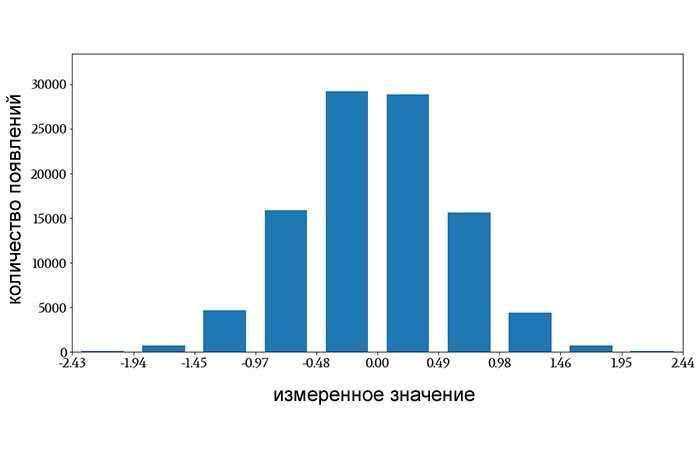
Следующая гистограмма, которая была сгенерирована из нормально распределенных данных со средним значением 0 и стандартным отклонением 0,6, использует интервалы вместо отдельных значений:
 Рисунок 2 – Гистограмма с использованием интервалов вместо отдельных значений
Рисунок 2 – Гистограмма с использованием интервалов вместо отдельных значений
Горизонтальная ось разделена на десять интервалов одинаковой ширины, и каждому интервалу назначен один столбец. Все результаты измерений, попадающие в числовой интервал, влияют на высоту соответствующего столбца (метки на горизонтальной оси показывают, что интервалы не одинаковой ширины, но это просто потому, что значения меток округлены).
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
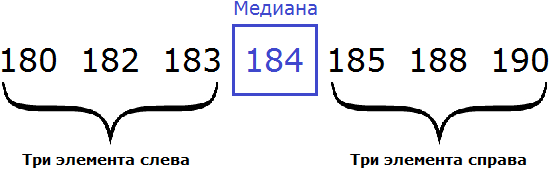
180, 182, 183, 184, 185, 188, 190
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану
Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186
Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190
![]()
Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2
![]()
По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 6
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Средняя скорость движения
При изучении задач на движение мы определяли скорость движения следующим образом: делили пройденное расстояние на время. Но тогда подразумевалось, что тело движется с постоянной скоростью, которая не менялась на протяжении всего пути.









В реальности, это происходит довольно редко или не происходит совсем. Тело, как правило, движется с различной скоростью.
Когда мы ездим на автомобиле или велосипеде, наша скорость часто меняется. Когда впереди нас помехи, нам приходиться сбавлять скорость. Когда же трасса свободна, мы ускоряемся. При этом за время нашего ускорения скорость изменяется несколько раз.
Речь идет о средней скорости движения. Чтобы её определить нужно сложить скорости движения, которые были в каждом часе/минуте/секунде и результат разделить на время движения.
Задача 1. Автомобиль первые 3 часа двигался со скоростью 66,2 км/ч, а следующие 2 часа — со скоростью 78,4 км/ч. С какой средней скоростью он ехал?

Сложим скорости, которые были у автомобиля в каждом часе и разделим на время движения (5ч)
![]()
Значит автомобиль ехал со средней скоростью 71,08 км/ч.
Определять среднюю скорость можно и по другому — сначала найти расстояния, пройденные с одной скоростью, затем сложить эти расстояния и результат разделить на время. На рисунке видно, что первые три часа скорость у автомобиля не менялась. Тогда можно найти расстояние, пройденное за три часа:
66,2 × 3 = 198,6 км.
Аналогично можно определить расстояние, которое было пройдено со скоростью 78,4 км/ч. В задаче сказано, что с такой скоростью автомобиль двигался 2 часа:
78,4 × 2 = 156,8 км.
Сложим эти расстояния и результат разделим на 5
![]()
Задача 2. Велосипедист за первый час проехал 12,6 км, а в следующие 2 часа он ехал со скоростью 13,5 км/ч. Определить среднюю скорость велосипедиста.

Скорость велосипедиста в первый час составляла 12,6 км/ч. Во второй и третий час он ехал со скоростью 13,5. Определим среднюю скорость движения велосипедиста:
![]()
Смотри также
Wikimedia Foundation
.
2010
.
- Yat-Kha
- Амальгама (значения)
Смотреть что такое «Статистические методы» в других словарях:
СТАТИСТИЧЕСКИЕ МЕТОДЫ
— СТАТИСТИЧЕСКИЕ МЕТОДЫ научные методы описания и изучения массовых явлений, допускающих количественное (численное) выражение. Слово “статистика” (от игал. stato государство) имеет общий корень со словом “государство”. Первоначально оно… … Философская энциклопедия
СТАТИСТИЧЕСКИЕ МЕТОДЫ –
— научные методы описания и изучения массовых явлений, допускающих количественное (численное) выражение. Слово «статистика» (от итал. stato – государство) имеет общий корень со словом «государство». Первоначально оно относилось к науке управления и … Философская энциклопедия
Статистические методы
— (в экологии и биоценологии) методы вариационной статистики, позволяющие исследовать целое (напр., фитоценоз, популяцию, продуктивность) по его частным совокупностям (напр., по данным, полученным на учетных площадках) и оценить степень точности… … Экологический словарь
статистические методы
— (в психологии) (от лат. status состояние) нек рые методы прикладной математической статистики, используемые в психологии в основном для обработки экспериментальных результатов. Основная цель применения С. м. повышение обоснованности выводов в… … Большая психологическая энциклопедия
Статистические методы
— 20.2. Статистические методы Конкретные статистические методы, используемые для организации, регулирования и проверки деятельности, включают, но не ограничиваются следующими: а) планированием экспериментов и факторный анализ; b) анализ дисперсии и … Словарь-справочник терминов нормативно-технической документации
СТАТИСТИЧЕСКИЕ МЕТОДЫ
— методы исследования количеств. стороны массовых обществ. явлений и процессов. С. м. дают возможность в цифровом выражении характеризовать происходящие изменения в обществ. процессах, изучать разл. формы социально экономич. закономерностей, смену… … Сельско-хозяйственный энциклопедический словарь
СТАТИСТИЧЕСКИЕ МЕТОДЫ
— некоторые методы прикладной математической статистики, используемые для обработки экспериментальных результатов. Ряд статистических методов был разработан специально для проверки качества психологических тестов, для применения в профессиональном… … Профессиональное образование. Словарь
СТАТИСТИЧЕСКИЕ МЕТОДЫ
— (в инженерной психологии) (от лат. status состояние) некоторые методы прикладной статистики, используемые в инженерной психологии для обработки экспериментальных результатов. Основная цель применения С. м. повышение обоснованности выводов в… … Энциклопедический словарь по психологии и педагогике
Типы относительной частоты
Существует два типа относительной частоты: простая и кумулятивная. Начнем с первого.
простая относительная частота
Вот как рассчитать простую относительную частоту на примере.
Пример:
В классе с 50 учениками учитель физкультуры посоветовал им, какой вид спорта будет их любимым. Полученные ответы регистрировались по их абсолютной частоте:
-
футбол → 20 учеников
-
волейбол → 12 учеников
-
сожжено → 8 студентов
-
гандбол → 6 учеников
-
другие → 4 ученика
Разрешение:
Всего было собрано 50 ответов, поэтому для расчета относительной частоты каждого из них мы разделим количество появлений каждого ответа на 50.
Относительная частота:
-
футбол → 20: 50 = 0,4
-
волейбол → 12: 50 = 0,24
-
сожжено → 8: 50 = 0,16
-
гандбол → 6: 50 = 0,12
-
другие → 4: 50 = 0,08
Относительная частота может быть выражена десятичным числом, но обычно выражается в процентах. Чтобы преобразовать найденные десятичные числа в проценты, просто умножьте на 100, так что мы имеем:
-
футбол → 20: 50 = 0,4 = 40%
-
волейбол → 12: 50 = 0,24 = 24%
-
сожжено → 8: 50 = 0,16 = 16%
-
гандбол → 6: 50 = 0,12 = 12%
-
другие → 4: 50 = 0,08 = 8%
Эти данные обычно представляются в виде таблицы, известной как таблица частот:
|
Спорт |
абсолютная частота (ВЕНТИЛЯТОР) |
относительная частота (фр.) |
Относительная частота (%) (ФР%) |
|
Футбольный |
20 |
0,4 |
40% |
|
Волейбол |
12 |
0,24 |
24% |
|
Сгорел |
8 |
0,16 |
16% |
|
Гандбол |
6 |
0,12 |
12% |
|
Другие |
4 |
0,08 |
8% |
|
Всего |
50 |
1 |
100% |
Накопленная относительная частота
Как следует из названия, кумулятивная относительная частота накопление относительной частоты. Для его расчета необходимо сначала вычислить относительную частоту, как и в предыдущем примере.
С данными, организованными в таблице частот:
-
сначала вставляем в частотную таблицу еще один столбец;
-
затем копируем первую полученную относительную частоту;
-
мы выполняем в этом новом столбце и позже, чтобы найти другие накопленные частоты, сумму относительной частоты строки с накопленной частотой предыдущей строки.
|
Спорт |
абсолютная частота (ВЕНТИЛЯТОР) |
относительная частота (фр.) |
относительная частота накопленный |
|
Футбольный |
20 |
0,4 |
0,4 |
|
Волейбол |
12 |
0,24 |
0,4 + 0,24 = 0,64 |
|
Сгорел |
8 |
0,16 |
0,64 + 0,16 = 0,80 |
|
Гандбол |
6 |
0,12 |
0,80 + 0,12 = 0,92 |
|
Другие |
4 |
0,08 |
0,92 + 0,08 = 1 |
|
Всего |
50 |
1 |
Тогда мы можем отобразить таблицу частот следующим образом:
|
Спорт |
абсолютная частота (ВЕНТИЛЯТОР) |
относительная частота (фр.) |
относительная частота накопленный |
|
Футбольный |
20 |
0,4 |
0,4 |
|
Волейбол |
12 |
0,24 |
0,64 |
|
Сгорел |
8 |
0,16 |
0,80 |
|
Гандбол |
6 |
0,12 |
0,92 |
|
Другие |
4 |
0,08 |
1,00 |
|
Всего |
50 |
1 |
Эта кумулятивная относительная частота также может быть выражена в процентах:
|
Спорт |
Частота абсолютный (ВЕНТИЛЯТОР) |
Частота родственник (фр.) |
Частота родственник накопленный |
Частота родственник % (ФР%) |
Частота родственник накопленный % |
|
Футбольный |
20 |
0,4 |
0,4 |
40% |
40% |
|
Волейбол |
12 |
0,24 |
0,64 |
24% |
64% |
|
Сгорел |
8 |
0,16 |
0,80 |
16% |
80% |
|
Гандбол |
6 |
0,12 |
0,92 |
12% |
92% |
|
Другие |
4 |
0,08 |
1,00 |
8% |
100% |
|
Всего |
50 |
1 |
100% |
Примеры задачи на построение полигона и гистограммы
Пример 1
Пусть распределение частот имеет вид:
Рисунок 7.
Построить полигон относительных частот.
Построим сначала ряд распределения относительных частот по формуле $W_i=\frac{n_i}{n}$
Представляются в виде рядов распределения и оформляются в виде .
Ряд распределния является одним из видов группировок.
В зависимости от признака, положенного в основу образования ряда распределения различают атрибутивные и вариационные
ряды распределения:
-
Атрибутивными
— называют ряды распределения, построенные по качественными признакам. - Ряды распределения, построенные в порядке возрастания или убывания значений количественного признака называются вариационными
.
Вариационный ряд распределения состоит из двух столбцов:
В первом столбце приводятся количественные значения варьирующегося признака, которые называются вариантами
и обозначаются . Дискретная варианта — выражается целым числом. Интервальная варианта находится в пределах от и до. В зависимости от типа варианты можно построить дискретный или интервальный вариационный ряд.Во втором столбце содержится количество конкретных вариант
, выраженное через частоты или частости:



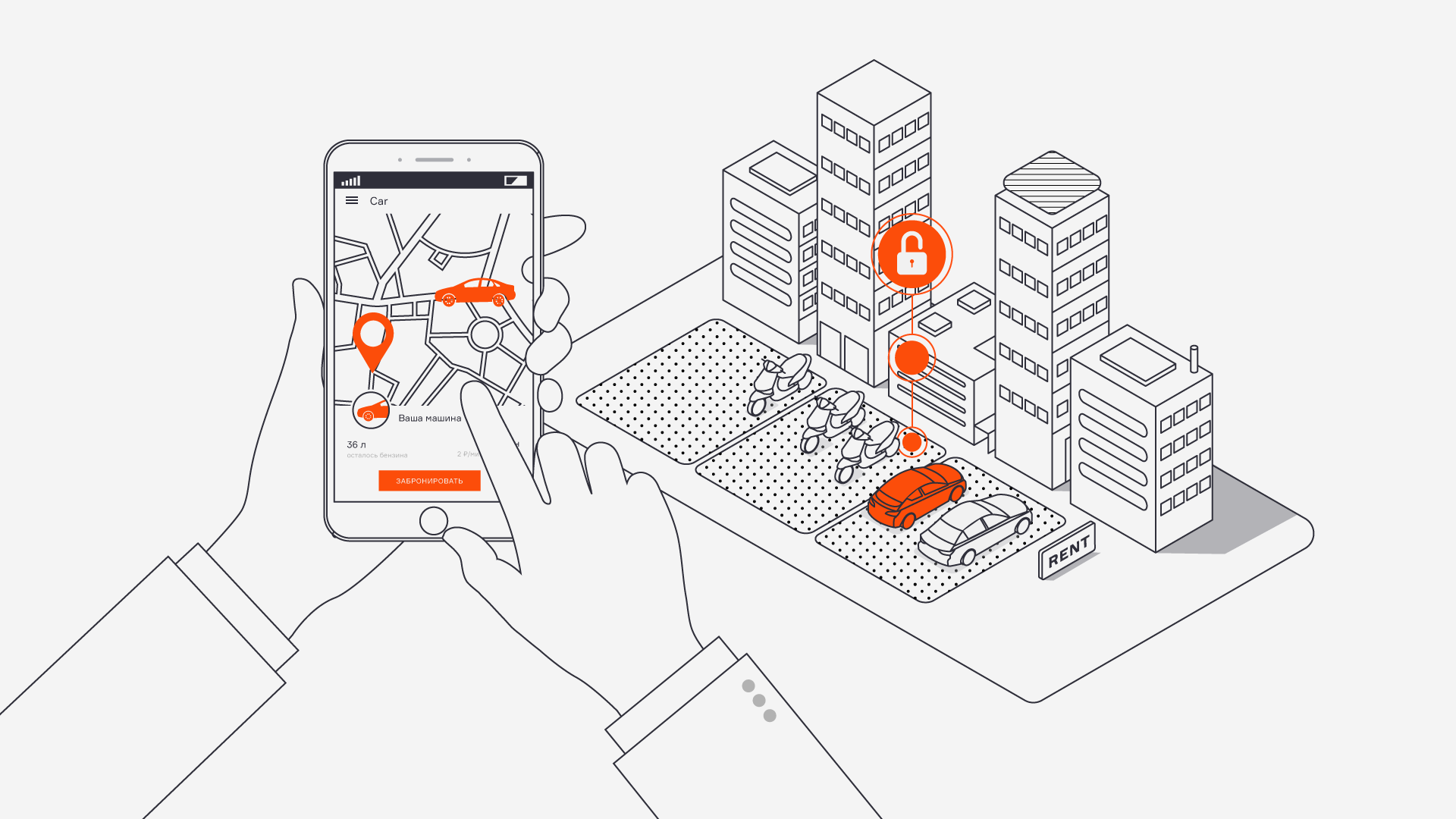


Графическое изображение рядов распределения
Наглядно ряды распределения представляются при помощи графических изображений.
Ряды распределения изображаются в виде:
- Полигона
- Гистограммы
- Кумуляты
- Огивы
Литература
2. Нейлор Т. Машинные имитационные эксперименты с моделями экономических систем. — М.: Мир, 1975. — 500 с.
3. Крамер Г. Математические методы статистики. — М.: Мир, 1948 (1-е изд.), 1975 (2-е изд.). — 648 с.
4. Большев Л. Н., Смирнов Н. В. Таблицы математической статистики. — М.: Наука, 1965 (1-е изд.), 1968 (2-е изд.), 1983 (3-е изд.).
5. Смирнов Н. В., Дунин-Барковский И. В. Курс теории вероятностей и математической статистики для технических приложений. Изд. 3-е, стереотипное. — М.: Наука, 1969. — 512 с.
6. Норман Дрейпер, Гарри Смит
Прикладной регрессионный анализ. Множественная регрессия = Applied Regression Analysis. — 3-е изд. — М.: «Диалектика» , 2007. — С. 912. — ISBN 0-471-17082-8
Принципы построения статистических группировок
Ряд наблюдений, упорядоченных по возрастанию, называется вариационным рядом
Группировочным признаком
При использовании персональных компьютеров для обработки статистических данных группировка единиц объекта производится с помощью стандартных процедур.
Одна из таких процедур основана на использовании формулы Стерджесса для определения оптимального числа групп:
k = 1+3,322*lg(N)
Где k – число групп, N – число единиц совокупности.
Длину частичных интервалов вычисляют как h=(x max -x min)/k
Затем подсчитывают числа попаданий наблюдений в эти интервалы, которые принимают за частоты n i . Малочисленные частоты, значения которых меньше 5 (n i В качестве новых значений вариант берут середины интервалов x i =(c i-1 +c i)/2.
Относительная частота
Относительная частота это в принципе та же самая частота, которая была рассмотрена ранее, но только выраженная в процентах.
Относительная частота равна отношению частоты на общее число элементов выборки.
Вернемся к нашей таблице:
Пять подтягиваний выполнили 4 человека из 36. Шесть подтягиваний выполнили 5 человек из 36. Восемь подтягиваний выполнили 10 человек из 36 и так далее. Давайте заполним таблицу с помощью таких отношений:

Выполним деление в этих дробях:

Выразим эти частоты в процентах. Для этого умножим их на 100. Умножение на 100 удобно выполнить передвижением запятой на две цифры вправо:

Теперь можно сказать, что пять подтягиваний выполнили 11% участников, 6 подтягиваний выполнили 14% участников, 8 подтягиваний выполнили 28% участников и так далее.
Понравился урок? Вступай в нашу новую группу Вконтакте и начни получать уведомления о новых уроках
Графические возможности пакета STATISTICA
В пакете существуют 2 типа графиков:
1) Quick Stat Graphs — быстрые графики, позволяющие построить графики для фиксированной заранее переменной . Эти графики могут быть построены практически из любого места пакета.
2) Custom Stat Graphs — пользовательские графики, в которых переменные и диапазон случаев (Cases)zyia которых эти графики могут быть построены задается пользователем и может быть изменен в процессе выполнения программы.
Щелчок по кнопке Graphs активизирует панель графики. Все возможности ее перечислены в пунктах меню.
Первый пункт Quick Stat Graphs позволяет строить графики только для той переменной, которая была выделена заранее. Следующая группа пунктов меню позволяет стоить пользовательские графики:
Stats 2D Graphs — двумерные графики
Stats 3D Sequenrial Graphs — трехмерные графики последовательностей
Stats 3D XYZ Graphs — трехмерные графики.
Полигон
При построении полигона на горизонтальной оси (ось абсцисс) откладывают значения варьирующего признака, а на вертикальной оси (ось ординат) — частоты или частости.
Полигон на рис. 6.1 построен по данным микропереписи населения России в 1994 г.
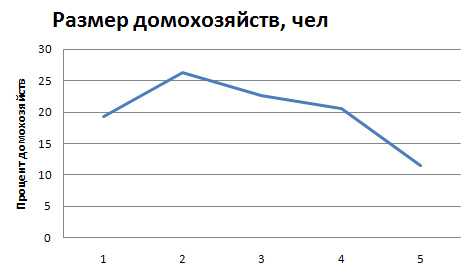
6.1. Распределение домохозяйств по размеру
Условие
: Приводятся данные о распределении 25 работников одного из предприятий по тарифным разрядам:4; 2; 4; 6; 5; 6; 4; 1; 3; 1; 2; 5; 2; 6; 3; 1; 2; 3; 4; 5; 4; 6; 2; 3; 4Задача
: Построить дискретный вариационный ряд и изобразить его графически в виде полигона распределения.Решение
:В данном примере вариантами является тарифный разряд работника. Для определения частот необходимо рассчитать число работников, имеющих соответствующий тарифный разряд.
Полигон используется для дискретных вариационных рядов.
Для построения полигона распределения (рис 1) по оси абсцисс (X) откладываем количественные значения варьирующего признака — варианты, а по оси ординат — частоты или частости.
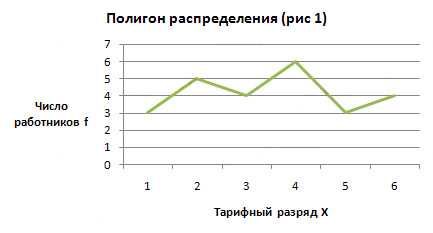
Если значения признака выражены в виде интервалов, то такой ряд называется интервальным.Интервальные ряды
распределения изображают графически в виде гистограммы, кумуляты или огивы.
Статистическая таблица
Условие
: Приведены данные о размерах вкладов 20 физических лиц в одном банке (тыс.руб) 60; 25; 12; 10; 68; 35; 2; 17; 51; 9; 3; 130; 24; 85; 100; 152; 6; 18; 7; 42.Задача
: Построить интервальный вариационный ряд с равными интервалами.Решение
:
- Исходная совокупность состоит из 20 единиц (N = 20).
- По формуле Стерджесса определим необходимое количество используемых групп: n=1+3,322*lg20=5
- Вычислим величину равного интервала: i=(152 — 2) /5 = 30 тыс.руб
- Расчленим исходную совокупность на 5 групп с величиной интервала в 30 тыс.руб.
- Результаты группировки представим в таблице:
При такой записи непрерывного признака, когда одна и та же величина встречается дважды (как верхняя граница одного интервала и нижняя граница другого интервала), то эта величина относится к той группе, где эта величина выступает в роли верхней границы.
Методы анализа статистических данных
В анализе статистических данных можно выделить аналитический этап и описательный. Описательный этап — последний, он включает представление собранных данных в удобном графическом виде – в графиках, диаграммах, дашбордах. Аналитический этап — это анализ, заключающийся в использовании одного из следующих методов:
- статистического наблюдения – систематического сбора данных по интересующим характеристикам;
- сводки данных, в которой можно обработать информацию после наблюдения; она описывает отдельные факты как часть общей совокупности или создает группировки, делит информацию по группам на основании каких-либо признаков;
- определении абсолютной и относительной статистической величины; абсолютная величина придает данным количественные характеристики в индивидуальном порядке, в независимости от других данных; относительные величины описывают одни объекты или признаки относительно других;
- метода выборки – использовании при анализе не всех данных, а только их части, отобранной по определенным правилам (выборка может быть случайной, стратифицированной, кластерной и квотной);
- корреляционного и регрессионного анализа — выявляет взаимосвязи данных и причины, по которым данные зависят друг от друга, определяет силу этой зависимости;
- метода динамических рядов — отслеживает силу, интенсивность и частоту изменений объектов и явлений; позволяет оценить данные во времени и дает возможность прогнозирования явлений.
Полигональная графика интеллектуальна
Это визуализация осознанной формы. Художникам и дизайнерам полигон помогает упростить, осмыслить, а значит, в дальнейшем правильно передать форму и объем объекта.
Помогает он и в трехмерной графике. Там полигон — это минимальная поверхность, элемент, из которого складываются каркасы форм любой сложности. Чем больше полигонов, тем более детализованной будет модель. В трехмерной графике в качестве полигонов обычно применяют треугольники.
Полигоны — простые, красивые, лаконичные и бесконечно многообразные вдохновляют многих современных дизайнеров. Из них можно составлять абстрактные композиции и стильные иллюстрации любой сложности


В этой статье вы узнаете много нового о полигонах и полигональной графике и увидите замечательные примеры ее использования. Также здесь собрано несколько уроков, которые помогут вам освоить эту технику.


Виды статистических группировок
Вариационный ряд
-
Типологическая группировка
– это разделение исследуемой качественно разнородной совокупности на классы, социально–экономические типы, однородные группы единиц. Для построения данной группировки используйте параметр Дискретный вариационный ряд. -
Структурной называется группировка
, в которой происходит разделение однородной совокупности на группы, характеризующие ее структуру по какому–либо варьирующему признаку. Для построения данной группировки используйте параметр Интервальный ряд. - Группировка, выявляющая взаимосвязи между изучаемыми явлениями и их признаками, называется аналитической группировкой
(см. аналитическая группировка ряда).
7.1 Выборочное среднее
Для конкретной выборки объема n ее выборочное среднее определяется соотношениемгде хi – значение элемента выборки.Обычно требуется описать статистические свойства произвольных случайных выборок одного объема, а не одной из них. Это значит, что рассматривается математическая модель, которая предполагает достаточно большое количество выборок объема n. В этом случае элементы выборки рассматриваются как независимые случайные величины Хi, принимающие значения хi с одной и тоже плотностью вероятностей f(x), являющейся плотностью вероятностей генеральной совокупности. Тогда выборочное среднее также является случайной величиной , равнойСреднее значение генеральной совокупности, из которой производится выборка, будем называть генеральным средним и обозначать mх. При значительном объеме выборки можно ожидать, что выборочное среднее не будет заметно отличаться от генерального среднего. Поскольку выборочное среднее является случайной величиной, то для нее можно найти математическое ожидание:Таким образом, математическое ожидание выборочного среднего равно генеральному среднему. В этом случае говорят, что выборочное среднее является несмещенной оценкой генерального среднего. В дальнейшем мы вернемся к этому термину. Так как выборочное среднее является случайной величиной, флуктуирующей вокруг генерального среднего, то желательно оценить эту флуктуацию с помощью дисперсии выборочного среднего. Рассмотрим выборку, объем которой n значительно меньше объема генеральной совокупности N (n << N). Предположим, что при формировании выборки характеристики генеральной совокупности не меняются, что эквивалентно предположению N = ¥. Тогда
Случайные величины Хi и Xj (i¹j) независимы, следовательно,Подставим полученный результат в формулу для дисперсии:, где – дисперсия генеральной совокупности. Тогда среднее квадратическое отклонение выборочного среднего равно:.Из этой формулы следует, что с увеличением объема выборки флуктуации среднего выборочного около среднего генерального уменьшаются как . Проиллюстрируем сказанное примером. Пусть имеется случайный сигнал с математическим ожиданием и дисперсией, соответственно равными mx = 10, = 9.Отсчеты сигнала берутся в равноотстоящие моменты времени t1, t2, … , tn.Так как отсчеты являются случайными величинами, то будем их обозначать X(t1), X(t2), … , X(tn).Определим количество отсчетов, чтобы среднее квадратическое отклонение оценки математического ожидания сигнала не превысило 1% его математического ожидания. Поскольку mx=10, то нужно, чтобы С другой стороны поэтому или Отсюда получаем, что n ³ 900 отсчетов.
Вероятностно-статистическое моделирование
При применении статистических методов в конкретных областях знаний и отраслях народного хозяйства получаем научно-практические дисциплины типа «статистические методы в промышленности», «статистические методы в медицине» и др. С этой точки зрения эконометрика — это «статистические методы в экономике». Эти дисциплины группы б) обычно опираются на вероятностно-статистические модели, построенные в соответствии с особенностями области применения. Весьма поучительно сопоставить вероятностно-статистические модели, применяемые в различных областях, обнаружить их близость и вместе с тем констатировать некоторые различия. Так, видна близость постановок задач и применяемых для их решения статистических методов в таких областях, как научные медицинские исследования, конкретные социологические исследования и маркетинговые исследования, или, короче, в медицине , социологии и маркетинге . Они часто объединяются вместе под названием «выборочные исследования».
Отличие выборочных исследований от экспертных проявляется, прежде всего, в числе обследованных объектов или субъектов — в выборочных исследованиях речь обычно идет о сотнях, а в экспертных — о десятках. Зато технологии экспертных исследований гораздо изощреннее. Еще более выражена специфика в демографических или логистических моделях, при обработке нарративной (текстовой, летописной) информации или при изучении взаимовлияния факторов.
Вопросы надежности и безопасности технических устройств и технологий, теории массового обслуживания подробно рассмотрены, в большом количестве научных работ.