Генеральная средняя
Пусть нам дана генеральная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 1
Генеральная совокупность — совокупность случайно отобранных объектов данного вида, над которыми проводят наблюдения с целью получения конкретных значений случайной величины, проводимых в неизменных условиях при изучении одной случайной величины данного вида.
Определение 2
Генеральная средняя — среднее арифметическое значений вариант генеральной совокупности.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда генеральная средняя вычисляется по формуле:
Получи помощь с рефератом от ИИ-шки
ИИ ответит за 2 минуты
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае генеральная средняя вычисляется по формуле:
15.4 Эксцесс
Коэффиент эксцесса (excess kurtosis) показывает отсроту пика распределения. Как мы говорили , коэффициент эксцесса связан с четвертым центральным моментом распределения, поэтому выборочный коэффициент эксцесса также рассчитывается на его основе.
\
Что в формуле коэффициента эксцесса делает \(-3\)?
Коэффициент эксцесса, как и коэффициент асимметрии, может принимать положительные, отрицательные или нулевые значения.
- нулевой коэффициент эксцесса обозначает такой же эксцесс, как у стандартного нормального распределения (то есть, «нормальный»)
- положительный коэффициент эксцесса обозначает, что распределение имеет более острую вершину (то есть у нас очень много средних значений, но тонкие «хвосты» — мало низких и высоких значений)
- отрицательный коэффициент эксцесса обозначает, что распределение имеет более пологую вершину (то есть у нас меньше средних значений и толстые «хвосты» — много низких и высоких значений)
Для чего применяют исправленную выборочную дисперсию
Исправленную выборочную используют для точечной оценки генеральной дисперсии.
Пример
Длину стержня измерили одним и тем же прибором пять раз. В результате получили следующие величины: 92 мм, 94 мм, 103 мм, 105 мм, 106 мм. Задача найти выборочную среднюю длину предмета и выборочную исправленную дисперсию ошибок измерительного прибора.
Решение
Сначала вычислим выборочную среднюю:
\({\overline x}_В=\frac{92+94+103+105+106}5=100\)
Затем найдем выборочную дисперсию:
\(D_В=\frac{\displaystyle\sum_{i=1}^k{(x_i-{\overline x}_В)}^2}n=\frac{{(92-100)}^2+{(94-100)}^2+{(103-100)}^2+{(105-100)}^2+{(106-100)}^2}5=34\)
Теперь рассчитаем исправленную дисперсию:
Квантильный график
До проверки критериев мы делаем визуальный анализ данных. Согласия хорошо проверять с помощью гистограммы. Но по ней довольно сложно судить о правильности убывания хвостов. Чтобы это проверить был придуман квантильный график
Согласие выборки с распределением, которое образовано с помощью сдвига/масштаба, можно проверить визуально с помощью квантильного графика (Q-Q Plot). К таким распределениям относятся: равномерное, экспоненциальное, нормальное и т.д.
На квантильном графике имеются точки, которые должны расположится вдоль некоторой прямой. Если они располагаются как на графике ниже — тогда у нас отличное согласие.
Выборочная средняя
Пусть нам дана выборочная совокупность относительно случайной величины $X$. Для начала напомним следующее определение:
Определение 3
Выборочная совокупность — часть отобранных объектов из генеральной совокупности.
Определение 4
Выборочная средняя — среднее арифметическое значений вариант выборочной совокупности.
Пусть значения вариант $x_1,\ x_2,\dots ,x_k$ имеют, соответственно, частоты $n_1,\ n_2,\dots ,n_k$. Тогда выборочная средняя вычисляется по формуле:
Рассмотрим частный случай. Пусть все варианты $x_1,\ x_2,\dots ,x_k$ различны. В этом случае $n_1,\ n_2,\dots ,n_k=1$. Получаем, что в этом случае выборочная средняя вычисляется по формуле:
!!! В случае, когда значение вариант не являются дискретными, а представляют из себя интервалы, то в формулах для вычисления генеральной или выборочной средних значений за значение $x_i$ принимается значение середины интервала, которому принадлежит $x_i.$
Исправленная дисперсия
Математически выборочная дисперсия не соответствует генеральной, поскольку выборочная используется для смещенного оценивания генеральной дисперсии. По этой причине математическое ожидание выборочной дисперсии вычисляется так:
\(M\left=\frac{n-1}nD_Г\)
В данной формуле DГ – это истинное значение дисперсии генеральной совокупности.
Исправить выборочную дисперсию можно путем умножения ее на дробь:
\(\frac n{n-1}\)
Получим формулу следующего вида:
\(S^2=\frac n{n-1}\cdot D_В=\frac{\displaystyle\sum_{i=1}^kn_i{(x_i-{\overline x}_В)}^2}{n-1}\)
Исправленная дисперсия используется для несмещенной оценки генеральной дисперсии и обозначается S2.
Среднеквадратическая генеральная совокупность оценивается при помощи исправленного среднеквадратического отклонения, которое вычисляется по формуле:
\(S=\sqrt{S^2}\)
При нахождении выборочной и исправленной дисперсии разнятся лишь знаменатели в формулах. Различия в этих характеристиках при больших n незначительны. Применение исправленной дисперсии целесообразно при объеме выборки меньше 30.
Дисперсия выборки. Стандартное отклонение
Дисперсией величины называется среднее значение квадрата отклонения величины от её среднего значения. Дисперсию генеральной совокупности рассчитывают по формуле:
(4)
Дисперсию выборки рассчитывают по формуле:
(5)
для негруппированных выборок и
(6)
для группированных выборок.
Пример 3. В таблице – данные о возрасте жителей административной территории Т в 2013 году.
Не будем приводить эту таблицу из-за её громоздкости. Отметим лишь, что в таблице дана численность
каждого из возрастов (по одному году, например, 33 года, 40 лет, 65 лет и т.д.) в группах от 0 лет по 94 года (включительно) и численность всей возрастной группы
в интервале 95-99 лет, а также численность жителей старше 100 лет.
Требуется найти средний возраст жителей административной территории и дисперсию среднего возраста.
Решение. Найдём средний возраст. Так как данные в таблице являются данными генеральной совокупности, находим средний возраст генеральной совокупности:
В таблице – данные о числе жителей каждого возраста, исключение же – жители в возрасте 95-99 лет и старше 100 лет. Поэтому рассчитали центр интервала возрастной группы 95-99 лет: 97 лет и в расчётах использовали его.
Так как число жителей старше 100 лет относительно небольшое, чтобы упростить расчёты, нижнюю границу интервала приняли за значение признака.
Итак, средний возраст жителей административной территории Т – 38,2 года
Найдём теперь его дисперсию:
Пример 4. Найти дисперсию урожайности зерновых в сельских хозяйствах, используя данные примера 2.
Решение. Средняя урожайность по выборке составляет 15,6 центнеров с га. Чтобы найти дисперсию, создадим дополнительную таблицу.
|
Центры интервалов |
Число хозяйств |
|||
|
2,5 |
4244 |
-13,1 |
172,1 |
730412,3 |
|
7,5 |
10446 |
-8,1 |
65,9 |
688558,6 |
|
12,5 |
18956 |
-3,1 |
9,7 |
184391,3 |
|
17,5 |
20207 |
1,9 |
3,5 |
71505,7 |
|
22,5 |
8159 |
6,9 |
47,3 |
386328,5 |
|
27,5 |
4165 |
11,9 |
141,2 |
585113,6 |
|
32,5 |
1316 |
16,9 |
285,0 |
375024,0 |
|
37,5 |
792 |
21,9 |
478,8 |
379196,9 |
|
42,5 |
183 |
26,9 |
722,6 |
132234,9 |
|
47,5 |
182 |
31,9 |
1016,4 |
184986,0 |
|
52,5 |
161 |
36,9 |
1360,2 |
218995,1 |
|
Всего |
68791 |
— |
— |
393679,1 |
Теперь у нас есть всё, чтобы найти дисперсию:
Пример 5. Найти дисперсию температуры в населённом пункте N в 2009 году, используя данные примера 1.







Решение. Данная выборка – негруппированная, найдём дисперсию температуры для негруппированной выборки:
Стандартное отклонение равно положительному корню из дисперсии. Стандартное отклонение генеральной совокупности находят по формуле
(7)
Стандартное отклонение выборки находят по формуле
. (9)
для негруппированных выборок и
(10)
для группированных выборок.
Определение эмпирической функции распределения
Пусть $X$ — случайная величина. $F(x)$ — функция распределения данной случайной величины. Будем проводить в одних и тех же независимых друг от друга условий $n$ опытов над данной случайной величиной. При этом получим последовательность значений $x_1,\ x_2\ $, … ,$\ x_n$, которая и называется выборкой.
Определение 1
Каждое значение $x_i$ ($i=1,2\ $, … ,$ \ n$) называется вариантой.
Определение 2
Функция распределения $F(x)$ генеральной совокупности называется теоретической функцией распределения.
Одной из оценок теоретической функции распределения является эмпирическая функция распределения.
Статья: Эмпирическая функция распределения
Найди решение своей задачи среди 1 000 000 ответов
Определение 3
Эмпирической функцией распределения $F_n(x)$ называется функция, которая определяет для каждого значения $x$ относительную частоту события $X
\
где $n_x$ — число вариант, меньших $x$, $n$ — объем выборки.
Отличие эмпирической функции от теоретической состоит том, что теоретическая функция определяет вероятность события $X
Погрешности выборки
Погрешности выборки характеризуют, насколько значительная ошибка допущена при замещении генеральной совокупности выборкой. Сколь бы тщательно ни подбирали выборку, параметр генеральной совокупности и оценка выборки Т всегда будут отличаться. Их разница является погрешность выборки .
Среднюю стандартную погрешность выборки находят по формуле
(11)
Средняя стандартная погрешность выборки характеризует рассеяние средних арифметических выборки по отношению к средним генеральной совокупности: чем больше погрешность, тем дальше среднее арифметическое выборки может находиться от среднего генеральной совокупности. В свою очередь, чем меньше погрешность, тем ближе к среднему генеральной совокупности находится среднее выборки. При увеличении числа наблюдений n стандартная погрешность уменьшается.
Стандартную погрешность называют также абсолютной погрешностью средней величины и нередко записывают .
Пример 6. Найти стандартную погрешность средней урожайности сельских хозяйств и интервал оценки, используя результаты примеров 2 и 4.
Решение. В примере 2 найдена средняя урожайность зерновых, равная 15,6 центнеров с га. В примере 4 найдена дисперсия урожайности, равная 57,2. Найдём стандартное отклонение урожайности:
Найдём теперь стандартную погрешность:
Интервал оценки средней урожайности:
| Назад | Листать | Вперёд>>> |
Всё по теме «Математическая статистика»
Зависимые выборки
Двухвыборочный t-критерий Стьюдента
В некоторых случаях связанные выборки имеют элементы Xi и Yi
соответствуют одному и тому же объекту, но измерения сделаны в
разные моменты (например, до и после применения лекарства).
Размеры выборок в этом случае должны совпадать:
n1 = n2 = n
Рассмотрим выборку, образованную разностями Xi и Yi
Zi = Yi − Xi, i = 1, . . . , n.
Сравнение средних в зависимых выборках ничем не отличается от сравнения среднего разности Zi с нулём.
- Выборки: X = (X1, . . . , Xn1), Y = (Y1, . . . , Yn2), Zi = Yi − Xi и Zi ∼ N (µ, σ2). При этом X, Y зависимые, σ неизвестна
- Нулевая гипотеза: H : µ = 0
- Альтернатива: H1 : µ ≠ 0 или µ > 0, или µ < 0
- Нулевое распределение: Tn ∼ tn−1
Далее, чтобы сформулировать непараметрические критерии, возьмем каждое приращение Zi и разложим их на две части:
Zi = θ + εi, i = 1, . . . , n
где θ — систематический сдвиг, который не зависит от человека, а εi — случайные ошибки, включающие в себя влияние неучтенных факторов на Zi
В данных обозначениях нулевую гипотезу H можно записать как H: θ = 0. Мы будем предполагать, что ε1, . . . , εn независимы и имеют непрерывные и разные распределения с равной нулю медианой.
Критерий знаков
Самым простым непараметрическим критерием однородности для двух зависимых выборок является критерий знаков. Статистикой критерия знаков является величина
При верной H статистика Sn будет иметь биномиальное распределение Bin(n, 1/2), т.е. с успехом 1/2. Для больших n можно использовать сходимость к нормальному закону.
- Выборки: X = (X1, . . . , Xn1), Xi ∼ FX, Y = (Y1, . . . , Yn2), Yi ∼ FY, Zi = Yi − Xi и Zi = θ + εi
- Нулевая гипотеза: H : θ = 0
- Альтернатива: H1 : θ ≠ 0 или θ > 0, или θ < 0
- Нулевое распределение: Sn ∼ Bin(n, 1/2)
Критерий знаковых рангов Уилкоксона
Предположим, что случайные величины ε1, . . . , εn имеют одинаковое распределение, симметричное относительно медианы (или же нуля). Условие строгой симметрии относительно медианы является почти столь же нереалистичным, как и предположение, что распределение величин Zi в точности нормально. Как правило, надежно проверить симметрию можно лишь по выборке из нескольких сотен наблюдений
Критерий знаковых рангов Уилкоксона основан на статистике
Wn = R1U1 + . . . + RnUn,
где Ui = I{Zi>0}и Ri — ранги величин |Zi| в ряду |Z1|, . . . , |Zn|.
При верной H статистика Wn будет иметь табличное распределение (его можно посчитать явно). Для больших n можно использовать сходимость к нормальному
закону.
Свойства эмпирической функции распределения
Рассмотрим теперь несколько основных свойств функции распределения.
-
Область значений функции $F_n\left(x\right)$ — отрезок $$.
-
$F_n\left(x\right)$ неубывающая функция.
-
$F_n\left(x\right)$ непрерывная слева функция.
-
$F_n\left(x\right)$ кусочно-постоянная функция и возрастает только в точках значений случайной величины $X$
-
Пусть $X_1$ — наименьшая, а $X_n$ — наибольшая варианта. Тогда $F_n\left(x\right)=0$ при ${x\le X}_1$и $F_n\left(x\right)=1$ при $x\ge X_n$.
Введем теорему, которая связывает между собой теоретическую и эмпирическую функции.
Теорема 1
Пусть $F_n\left(x\right)$ — эмпирическая функция распределения, а $F\left(x\right)$ — теоретическая функция распределения генеральной выборки. Тогда выполняется равенство:
\
коэффициент вариации
– это отношение стандартного отклонения к средней, выраженное в процентах:
И вот теперь совершенно без разницы, в д.е. мы считали:
или в тысячах д.е.:
Примечание: на практике часто считают именно через , но для оценки коэффициента вариации всей генеральной совокупности, конечно же, корректнее использовать исправленное стандартное отклонение .
В статистике существует следующий эмпирический ориентир:
– если показатель вариации составляет примерно 30% и меньше, то статистическая совокупность считается однородной. Это означает, что большинство вариант находится недалеко от средней, и найденное значение хорошо характеризует центральную тенденцию совокупности.
– если показатель вариации составляет существенно больше 30%, то совокупность неоднородна, то есть, значительное количество вариант находятся далеко от , и выборочная средняя плохо характеризует типичную варианту. В таких случаях целесообразно рассмотреть , а иногда и перцентили, которые делят вариационный ряд на части, и для каждого участка рассчитать свои показатели. Но это уже немного дебри статистики.
Другое преимущество относительных показателей – это возможность сравнивать разнородные статистические совокупности. Например, множество слонов и множество хомячков. Совершенно понятно, что дисперсия веса слонов по отношению к дисперсии веса хомяков будет просто конской, и их сопоставление не имеет смысла. Но вот анализ коэффициентов вариации веса вполне осмыслен, и может статься, что у слонов он составляет 10%, а у хомячков 40% (пример, конечно, условный). Это говорит о сбалансированном питании и размеренной жизни слонов. А вот хомяки там, то носятся с голодухи по полям, то отъедаются и спят в норах, и поэтому среди них есть много худощавых и много упитанных особей ![]()
Кроме коэффициента вариации, существуют и другие относительные показатели, но в реальных студенческих работах они почти не встречаются, и поэтому я не буду их рассматривать в рамках данного курса.
И сейчас, конечно же, задачки для самостоятельного решения:
Пример 17, на отработку терминов и формул:
а) Стандартное отклонение выборочной совокупности равно 5, а средний квадрат её вариант – 250. Найти выборочную среднюю.








б) Определите среднее квадратическое отклонение, если известно, что средняя равна 260, а коэффициент вариации составляет 30%.
и Пример 18, творческий:
Производство стальных труб на предприятии (тонн) в 1-м полугодии составило:![]()
Определить:
– среднемесячный объем производства;
– среднее квадратическое отклонение;
– коэффициент вариации.
Сделать краткие содержательные выводы. – Да, это тоже типичный пункт статистической задачи!
Обратите внимание, что здесь не понятно, выборочной ли считать эту совокупность или генеральной. И в таких случаях лучше не заниматься домыслами, просто используем обозначения без подстрочных индексов
Вообще, задачи на экономическую и промышленную тематику – самые популярные в статистике, и в моей коллекции их сотни. Но все они до ужаса однотипны, и поэтому я предлагаю их в терапевтической дозировке ![]()
Задание 8
Выполнить расчёты в Экселе – числа уже там, ну а инструкцию я на этот раз не привёл, поскольку люди вы уже опытные.
Краткое решение и ответ в конце урока, который подошёл к концу.
Следующее занятие не за горами, а уже за кочкой:
Решения и ответы:
Пример 17. Решение:
а) Используем формулу . По условию, , . Таким образом:![]()
б) Используем формулу . По условию, , . Таким образом:
Ответ: а) , б)
Пример 18. Решение: вычислим сумму вариант и сумму их квадратов:Найдём среднюю: тонны – среднемесячный объем производства за полугодие.Дисперсию вычислим по формуле:![]() Среднее квадратическое отклонение: тонн.Коэффициент вариации:
Среднее квадратическое отклонение: тонн.Коэффициент вариации:
Ответ: тонны, тонн,
Краткие выводы: за первое полугодие среднемесячный объём производства труб составил тонны. Низкие показатели вариации говорят о стабильной ситуации на производстве.
(Переход на главную страницу)
Связь выборочной и генеральной дисперсии
Генеральная дисперсия представляет собой среднее арифметическое квадратов отступлений значений признаков генеральной совокупности от их среднего значения.
Осторожно! Если преподаватель обнаружит плагиат в работе, не избежать крупных проблем (вплоть до отчисления). Если нет возможности написать самому, закажите тут
Определение
Генеральная совокупность – это комплекс всех возможных объектов, относительно которых планируется вести наблюдение и формулировать выводы.
Выборочная совокупность или выборка является частью генеральной совокупности, выбранной для изучения и составления заключения касательной всей генеральной совокупности.
Основные понятия математической статистики
Математическая статистика – раздел математики, посвященный математическим методам систематизации, обработки и использованию статистических данных для научных и практических выводов. При этом статистическими данными называются сведения о числе объектов в какой-либо более или менее обширной совокупности, обладающих теми или иными признаками.
Статистическая совокупность, из которой отбирают часть объектов, называется генеральной совокупностью. Множество объектов, случайно отобранных из генеральной совокупности, называется выборкой. Число объектов N из генеральной совокупности и из выборки n называются соответственно объемом генеральной совокупности N и объемом выборки n.
Статистическое описание и вероятностные модели применяются к физическим, экономическим, социологическим, биологическим процессам, обладающим тем свойством, что хотя результат отдельного измерения физической величины X не может быть предсказан с достаточной точностью, но значение некоторой функции от множества результатов повторных измерений может быть предсказан с существенно лучшей точностью. Такая функция называется статистикой. Часто точность предсказания некоторой статистики возрастает с возрастанием объема выборки.
Наиболее известные статистики – относительная частота, выборочные средние, дисперсия. Когда возрастает объем выборки n, многие выборочные статистики сходятся по вероятности к соответствующим параметрам теоретического распределения величины X. Поэтому каждую выборку рассматривают как выборку из теоретически бесконечной генеральной совокупности, распределение признака в которой совпадает с теоретическим распределением вероятности случайной величины. Во многих случаях теоретическая генеральная совокупность есть идеализация действительной совокупности, из которой получена выборка.
Различные значения наблюдаемого признака, встречающегося в совокупности, называются
вариантами. Частоты вариантов выражают доли (удельные веса) элементов совокупности с одинаковыми
значениями признака. Вариационным рядом называется ранжированный в порядке возрастания
или убывания ряд вариантов с соответствующим им частотами.

Приближенный метод проверки нормальности распределения
Приближенный метод проверки нормальности распределения значений выборки основан на
следующем свойстве нормального распределения: коэффициент асимметрии
и коэффициент эксцесса равны нулю.
Коэффициент асимметрии
численно характеризует симметрию эмпирического распределения относительно среднего. Если коэффициент
асимметрии равен нулю, то среднее арифметрического значение, медиана и мода равны:
и кривая плотности
распределения симметрична относительно среднего. Если коэффициент асимметрии меньше нуля (),
то среднее арифметическое меньше медианы, а медиана, в свою очередь, меньше моды
() и кривая сдвинута
вправо (по сравнению с нормальным распределением). Если коэффициент асимметрии больше нуля (),
то среднее арифметическое больше медианы, а медиана, в свою очередь, больше моды
() и кривая сдвинута
влево (по сравнению с нормальным распределением).
Коэффициент эксцесса
характеризует концентрацию эмпирического распределения вокруг арифметического среднего в направлении
оси и степень островершинности кривой плотности распределения.
Если коэффициент эксцесса больше нуля, то кривая более вытянута (по сравнению с нормальным распределением)
вдоль оси (график более островершинный). Если коэффициент
эксцесса меньше нуля, то кривая более сплющена (по сравнению с нормальным распределением)
вдоль оси (график более туповершинный).
Коэффициент асимметрии можно вычислить с помощью функции MS Excel СКОС. Если вы
проверяете один массив данных, то требуется ввести диапазон данных в одно окошко «Число».
Коэффициент эксцесса можно вычислить с помощью функции MS Excel ЭКСЦЕСС. При проверке
одного массива данных также достаточно ввести диапазон данных в одно окошко «Число».
Итак, как мы уже знаем, при нормальном распределении коэффициенты асимметрии и эксцесса
равны нулю. Но что, если мы получили коэффициенты асимметрии, равные -0,14, 0,22, 0,43, а коэффициенты
эксцесса, равные 0,17, -0,31, 0,55? Вопрос вполне справедливый, так как практически мы имеем дело лишь с
приближенными, выборочными значениями асимметрии и эксцесса, которые подвержены некоторому неизбежному,
неконтролируемому разбросу. Поэтому нельзя требовать строгого равенства этих коэффициентов нулю, они
должны лишь быть достаточно близкими к нулю. Но что значит — достаточно?
Требуется сравнить полученные эмпирические значения с
допустимыми значениями. Для этого нужно проверить следующие неравенства (сравнить значения коэффициентов
по модулю с критическими значениями — границами области проверки гипотезы).
Для коэффициента асимметрии :
,
где
—
квантиль стандартного нормального распределения уровня ,
—
среднеквадратическое отклонение для выборки с числом наблюдений .
Для коэффициента эксцесса :
,
где
—
квантиль стандартного нормального распределения уровня ,
—
среднеквадратическое отклонение для выборки с числом наблюдений .
Так как коэффициенты асимметрии и эксцесса могут оказаться и положительными, и отрицательными,
то в приближенном методе проверки нормальности распределения используется двусторонний квантиль
стандартного нормального распределения; он задаёт интервал, в который случайная величина попадает
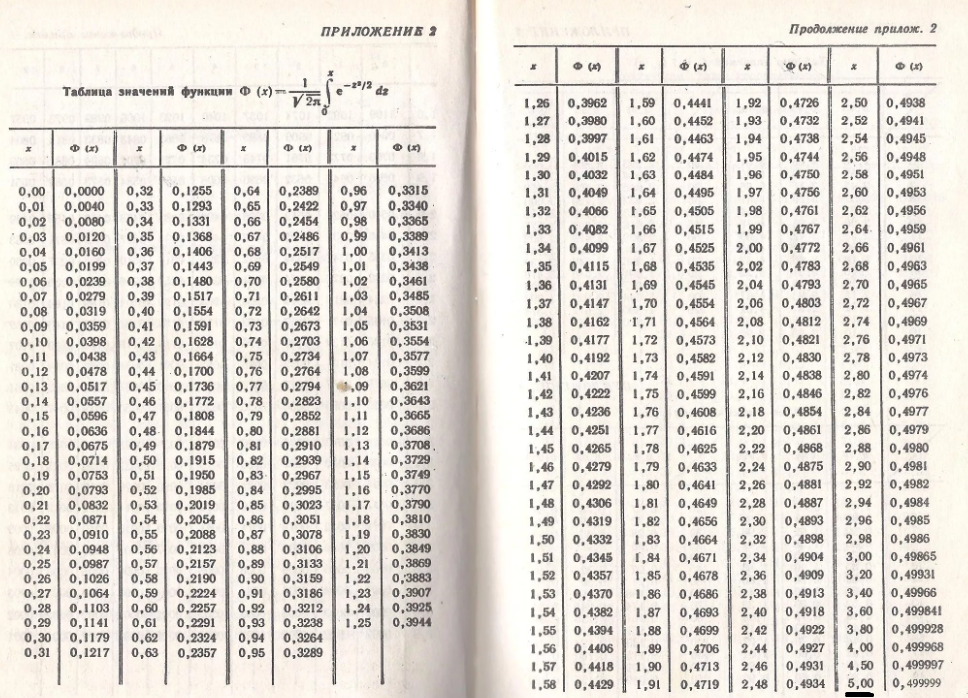
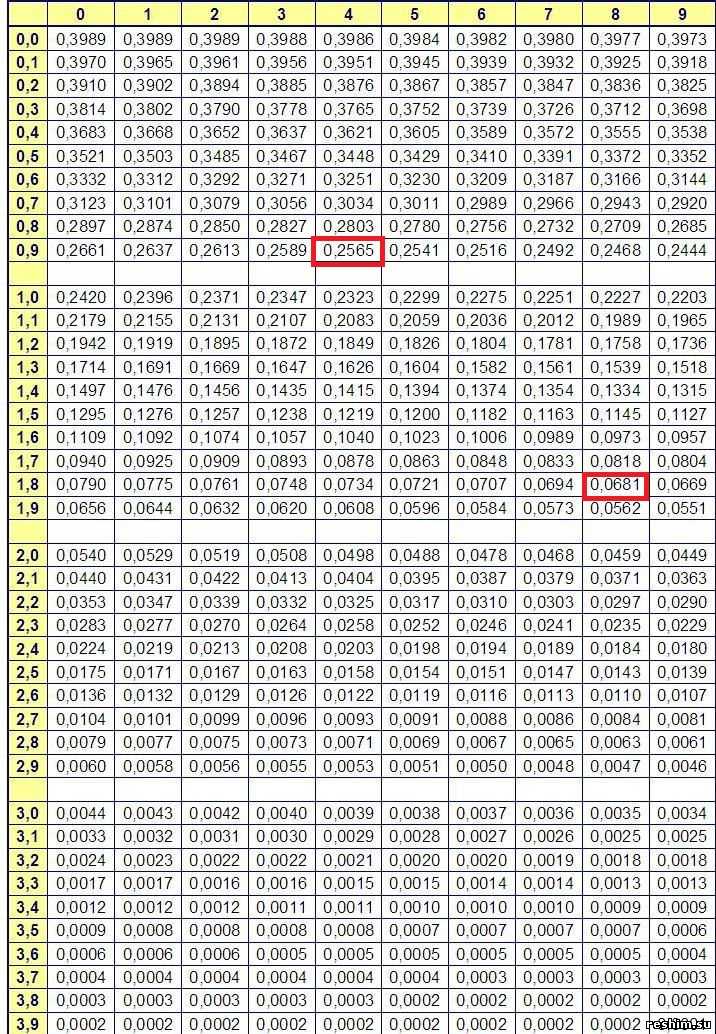
с определённой вероятностью. Приведём значения двусторонних квантилей стандартного нормального
распределения определённых уровней
(слева — уровень, справа — значение квантиля):
- 0,90: 1,645
- 0,95: 1,960
- 0,975: 2,241
- 0,98: 2,326
- 0,99: 2,576
- 0,995: 2,807
- 0,999: 3,291
- 0,9995: 3,481
- 0,9999: 3,891
Например, для выборки с числом наблюдений и
,
пользуясь этими значениями и ранее приведёнными формулами, можно получить границу области принятия гипотезы для
коэффициента асимметрии 0,62 и для коэффициента эксцесса 1,15. Поэтому приведённые ранее примеры эмпирических
значений коэффициента асимметрии -0,14, 0,22, 0,43 попадают в область принятия гипотезы. То же самое
относится к значениям коэффициента эксцесса 0,17, -0,31, 0,55. Следовательно, если получены такие
эмпирические значения, то с вероятностью 95% данные выборки подчиняются нормальному закону распределения.